Router

Router의 구조
1. input port
2. high-speed switching fabric
3. output port
routing processor는 control plane영역. software이다. 시간은 millisecond가 걸린다.
그 아래는 data plane영역. hardware이다. 시간은 nanosecond가 걸린다.
그렇다면 bottleneck은 routing processor가 된다. 여기서 input과 output의 forwarding은 nanosecond로 빠르지만, 그 중간에서 processing하는 routing processor가 millisecond로 느리기 떄문에 input port에 queueing delay가 생기게 된다.
Input port

physical layer(line termination) -> link layer -> queue -> switch fabric 로 datagram이 맨 밑 계층부터 올라옴.
queue에 datagram이 들어가 있는 동안, 맨 첫번째 datagram부터 IP header를 읽어서 어디로 보내야 할지를 찾는다. 그리고 Forwarding을 한다.
빨간 부분에서 input port에 들어온 것을 header의 field 값들을 이용해서 forwarding table을 보고, 어느 output port로 가야할지 찾는다.
*forwarding table : input port memory에 있다. datagram이 switch fabric으로 forward되는 시간보다 더 빠른 속도로 datagram이 도착하게 될 경우 결국 queueing이 된다.
결국 memory를 읽고 forwarding해야 하는데 방법이 두가지가 있다.
1. destination-based forwarding :

첫번째 칸은 11001000 … 00000000 부터 11001000 … 11111111까지는 link interface 0번으로 보내라는 것. 두번째 세번째 네번째도 마찬가지이다.
routing 알고리즘으로 범위가 설정되고, 어떤 주소에 대해서 어떤 interface를 통해 나가야 빨리 나가는지 학습해 나간다. 즉, router protocol을 통해 학습하는 것이다.
이것은 전세계 수많은 IP들을 전부 다 해준다. 학습해가면서 업데이트한다. IP주소의 범위는 대략적으로 국가적으로 나누어져 있다. 하지만 routing 알고리즘은 오버헤드가 상당히 크다.
Longest prefix matching

범위를 어떤식으로 나누게 되냐면, 첫번째 IP를 보자. 앞에서부터 8bit, 8bit, 5bit, 나머지 *으로 되어있다. *은 무엇이 오든 상관없다. 앞의 8,8,5bit만 보고 일치하면 0번 link로 보내는 것이다. 아래들도 마찬가지.
이때 Longest prefix matching을 사용하는데, 앞에서부터 쭉 봐서 제일 길게 matching이 되는 entry를 찾아서 이 entry에 해당하는 link로 datagram을 보내라고 hardwar switch한테 알려줌.

첫번째 주소는 어느 link로 가게 될까? 0번 link에 해당하는 entry이기 때문에 0번 link로 간다.
두번째 주소는? 1번 link로 가게 된다. 1번 link와 2번 link가 일치하지만, 1번 link entry가 더 길게 matching이 되기 때문에 1번 link로 보내진다.
이 수많은 entry는 메모리에 저장된다. 이 메모리는 ternary content addressable memories (TCAMs)라고 한다. 한번의 clock cycle에 하나의 주소를 가지고 있다.
Cisco Catalyst는 1M(백만개)의 routing table entry를 넣을 수 있다. (Cisco는 현재 전세계 라우터를 독점하고 있는 기업이다.)
2. generalized forwarding :
header field에 어떤 set들을 가지고 forwarding하는 방식이다.
Switching fabrics
패킷을 input buffer에서 output buffer로 전달하는 부분이다. switching rate라 하면 input에서 output으로 초당 몇 개의 패킷을 보내는 전송률이다. N개의 input이 있다면 line의 rate가 N배가 된다. 높을수록 성능이 좋다고 말한다. 여기 switching rate는 충분히 빠르다. (software 쪽에 비해서)

switching fabric은 크게 3가지가 있다.
1. memory : 가장 오래된 방식
2. bus : line을 공유하여 한번에 하나씩 보내는 방식
3. crossbar : line을 많이 사용하여 동시에 여러 개 보낼 수 있는 방식
1. memory

가장 전통적인 방식이다.
input port에 data를 memory에 넣었다가 output port로 보내는 형태이다. bus를 두번 지난다. (input -> memory, memory -> output)
이 방식은 memory의 bandwidth에 의해서 속도가 제한된다. 메모리(software)의 연산은 느리다. 결국 메모리를 사용한 이 방식은 느리다는 뜻이다.
2. bus
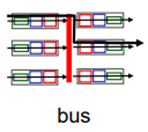
bus를 통해 스위치되는 방식이다.
bus contention이 있다. 즉, bus에서는 한번에 하나씩만 데이터가 전송되어야 한다. 결국 switching rate는 bus의 bandwidth에 의해 결정된다.
Cisco에서는 32Gbps의 bus를 붙여놓았다. 그래서 Switching rate가 32Gbps이다. 이 speed로 access network나 enterprise router에서 충분하다고 한다.
3. interconnection network (crossbar)

bus의 bandwidth를 극복하기 위해 등장했다. bus가 line 하나였다면 이 방식은 line을 여러 개 교차시켜 놓는다. 그래서 데이터를 동시에 보낼 수 있다. 그러나 line을 많이 두기 떄문에 Hardware적인 구현비용이 더 들어가게 된다.
Cisco는 이런 crossbar를 이용해서 60Gbps까지 끌어올렸다.
Input port queuing

Input port에서 datagram이 들어오는 것이 fabric로 보내는 것보다 빠르다면 input port에서 queueing이 생기게 된다. 심지어 input buffer가 overflow날 경우 드랍해버린다.
Head-of-the-Line(HOL) blocking이란 queue 맨 앞에 있는 것이 line의 head부분인데, 이 head가 나가지 못하면 뒤에거까지 못 나감을 말한다.
Output port

Output port에서도 Input과 마찬가지로 buffering이 된다. transmission하는 속도보다 들어오는 속도가 빠르면 buffering이 된다. 마찬가지로 손실도 날 수 있다.
그렇다면 buffer를 얼마나 주어야 할까? buffer를 많이 쓰면 delay가 엄청 늘어날 수 있다. 차라리 드랍시키는 게 낫다. 이와 같은 문제로 buffer의 크기는 중요하다.
buffer의 크기는 RTT * C(capacity) 로 정한다. 만약 N개의 flow가 있다면 (RTT*C)/sqrt(N) 이 buffer의 크기가 된다.
이 Output port에는 queueing 되어 있는 것들 중에 어떤 것부터 내보내는지에 대한 Scheduling 이슈가 있다.
Scheduling mechanisms
우선 queue에서 누구를 drop해야하는지 정하는 방법 3가지가 있다.
1. tail drop : 마지막으로 도착하는 얘를 드랍
2. priority : 우선순위 낮은 얘를 드랍
3. random : queue가 거의 찼을 때, 새로운 패킷이 온다면 원래 쌓여있던 얘들 중 랜덤하게 뽑아서 드랍. 실제 사용하는 방식임.
=> 끝에 오는 얘를 드랍하면, 무거운 파일을 보내면 계속해서 무거운 파일 얘들만 큐를 잡아먹고 있게된다. 이것은 형평성에 어긋난다. flow별로 골고루 드랍이 생기도록 한 것이다.
Scheduling policies: priority

우선 두 줄로 세운다. 그리고 high priority, low priority가 있으면, high를 중심으로 보내준다.
multiple class도 가능하다. 높은 순위의 class부터 보내준다.
IP에서는 이런 priority scheduling이 될수 있다고 생각해서 protocol을 설계했었다. 어느 큐에 보낼 것인지 나타내는 TOS field가 있다. 빨리 보낼 수 있는 줄에 보낼건지 판단하는 것이다. 실제 인터넷에서 사용하진 않는다.
1. Round Robin (RR)

여러 개의 class들이 있을 때 class queue들을 스캔해서 각각 class별로 한 개씩 끝내는 것이다. 돌려가면서 순차적으로 처리한다. 다만 class priority가 높은 경우 여러 번 돌리고, class priority가 낮은 경우 적게 돌린다.
2. Weighted Fair Queuing (WFQ)

queue를 복수개를 만들었을 떄, Round Robin인데 wait를 줘가지고 fair하게 하겠다. 빨간색은 priority가 높아서 wait를 두배로 주고, 녹색은 낮으니 한번만 주는 방식이다.
[참고]
Computer Networking A Top-Down Approach 7-th Edition / Kurose, Ross / Pearson
'IT > 네트워크' 카테고리의 다른 글
| 카페에서 와이파이가 끊기는 이유 (2) | 2020.05.20 |
|---|---|
| [ 네트워크 ] Internet Protocol : IP (IPv4) (2) | 2020.05.20 |
| [ 네트워크 ] Network layer (0) | 2020.05.13 |
| Wireshark 패킷 분석 (DNS, TCP) (2) | 2020.05.10 |
| [ 네트워크 ] Electronic mail (E-mail) (0) | 2020.05.04 |




댓글