Cache
순서
1. Cache 설명, 용어
2. Cache 구성
3. Indexing
4. Block offset
5. Tag
6. Tag matching
+ Write-back, Write-through
Cache 란?
Memory에 접근하는 것은 느리다. Processor가 연산하는 것이 훨씬 빠르다.
그래서 Memory에서 data를 읽고 쓰기 위해 access하는 성능이 느려서, 그동안 Processor는 놀고 있게 된다. Processor는 비싼 장비이니 최대한 써먹어야 한다.
따라서 자주 사용하는 데이터는 Memory까지 가지 말고 Processor 안에 미리 가져옴(Prefetching)와서 사용함으로써 Processor가 계속 바쁘게 돌아갈 수 있게 만드는 기술이다.
즉, Memory에 접근하는 비용을 줄이는 기법 중 하나이다.
Processor 입장에서는 Cache는 성능 개선 부분에서 굉장히 중요한 역할을 한다.
현대에서 HW를 뜯어봤을 때 점점 Processor의 상당 부분을 Cache가 차지하고 있는 추세인데, 이는 크게 두가지 이유가 있다.
1. Processor의 성능은 빨라지는데 Memory가 그만큼 못 따라오니 시간이 지나수록 성능 차이가 커져서 메워야할 차이가 커진다.
2. application이 점점 더 data를 많이 쓰게 되어 이를 커버하기 위해 Cache 의 크기가 커진다.
그리고 HW적으로 보자면 Cache는 SRAM이고, Memory는 DRAM이다.
SRAM은 access가 빠르지만 capacity가 커질 수 없고,
DRAM은 access가 느리지만 capacity가 더 크다.
Cache capacity
Cache의 capacity는 Memory의 Capacity보다 작다.
Cache의 capacity가 몇 MB 라면, Memory의 Capacity는 수~수십GB 일 것이다.
Cache의 capacity의 크기에 따라서 담을 수 있는 데이터가 결정된다.
capacity가 크면
장점: 많은 양의 데이터를 Cache 안에 보관할 수 있다.
단점: Cache 안에서 찾아야 할 데이터가 많아, 찾는데 시간이 오래 걸린다.
Cache block
1. Memory
Memory에 접근할 때는 address 기준으로 접근한다. Memory에 접근할 때 address로 data를 찾아서 가져오거나 기록하는 식이다. 이 때 address는 Byte 단위이다. 그래서 Memory를 Byte addressable하다고 이야기한다.
2. Cache
Cache는 Byte 보다 큰 chunk인 block 단위로 접근한다. 64Byte 또는 32Byte를 사용한다.
크게 사용하는 이유는, 매번 Memory를 access해서 data를 가져오는 것은 비용이 크다.
그래서 한번 memory에 접근할 때마다 한번에 많이 가져오는 것이다.
자세한 내용은 아래에 있음.
Hit, Miss
Cache 안에 내가 찾는 data가 있으면 Hit, 없으면 Miss 라고 한다.
Hit latency: 내가 접근하고자 하는 data가 Cache에 있을 때, 이 data를 가져오는 데 걸리는 시간.
L1은 1~3 cycle이 걸리고, L1에 없어서 L2로 갔을 때는 8~20 cycle이 걸린다. 그래서 최대한 L1 cache에 있으면 좋다. (L1 이 Processor와 더 가까움)
Miss latency: Cache 안에 data가 없어서 아래 단계 cache나 memory에서 data를 가져오는 데 걸리는 시간.
Cache의 구성
32KB의 Cache가 있다고 가정하고, Cache block size를 32 Byte라고 가정하자.
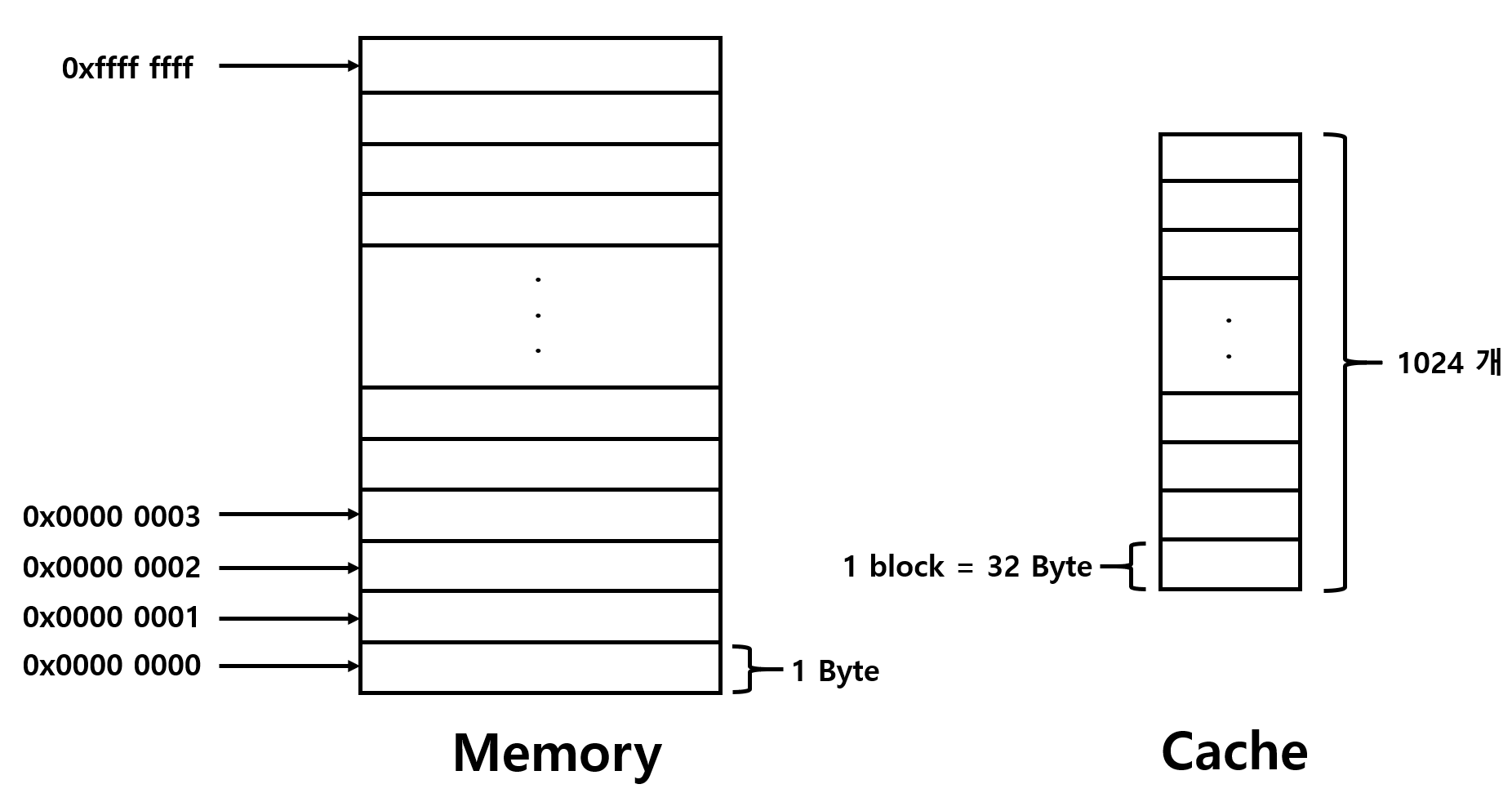
Memory는 address 단위로 접근하고, Cache는 block 단위로 접근한다.
Memory의 address는 32bit로 나타내고, 한 공간마다 1Byte의 address로 접근한다.
크기가 32 KByte이고, block size가 32Byte이니,
block의 개수는 32KByte / 32Byte = 1K개. 즉 1024개가 된다.
이러면 Cache는 32Byte 크기의 block이 1024개 있는 것이다.
이 block 마다 32 Byte의 정보를 담고 있는 것이다.
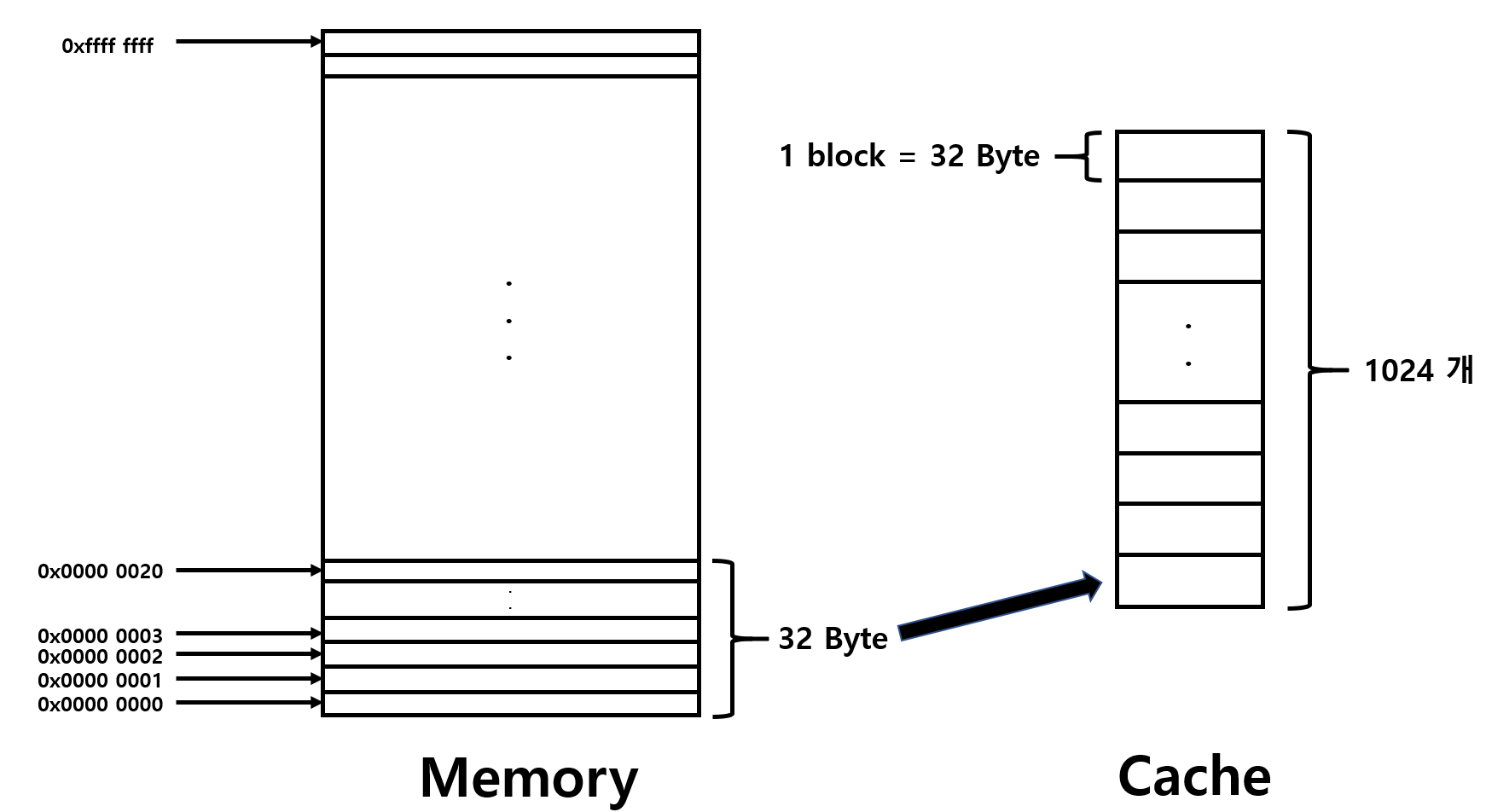
만약 Cache 안에 data가 없어서 Memory에 접근할 때 Memory의 몇번째 Byte인지 알아서 그 data를 가져올 것이다. 그 때 1Byte만 가져오는 것이 아니라 32Byte의 1block 단위로 가져오는 것이다.
여기서 32Byte를 가져온다는 것은, 여러 군데에서 32Byte를 가져온다는 것이 아니라, 연속된 메모리 주소 32Byte의 data를 가져오는 것이다.
cache는 보통 block size가 32Byte 또는 64Byte이다.
그렇다면 Memory는 1Byte단위로 접근하는데 Cache는 왜 이렇게 큰 단위로 접근할까?
1. Memory에서 data 가져오는데 비용이 많이 드니까 한번에 많이 가져오는 것이다.
2. Spatial locality가 있다. 다음 주소에 접근했을 때 이전에 가져왔던 것에서 사용할 확률 높다.
(참고) Spatial locality : 접근했던 data 근처에 있는 data들이 다음에 접근될 확률이 높다는 것을 말함
Indexing
Indexing이란 내가 접근하는 Memory address 에 대해 Cache 안의 1024개 공간 중에서 어디 있는지 찾는 방법이다.
위 그림의 Cache는 block이 총 1024개 있다.
1024 = 2^10 이니 1024를 표현하려면 10bit 가 필요하다.
이 10bit를 Memory address에서 뽑아와서 사용하는 것이 Indexing이다.
그러면 이 10bit로 0~1023 중에서 하나를 표현할 수 있다.

Memory address는 32bit이다. 32bit 중에서 어떤 10bit를 사용할까?
바로 5~14 번째 bit를 사용하게 된다.
만약 32KByte Cache가 아니라 64KByte Cache면??
block의 개수 = 64KByte / 32Byte = 2048 개이다.
그러므로 11개의 bit로 표현가능하고, 5~15 번째 bit를 사용하면 된다.
Block offset
위의 예시에서 Memory 부분을 봐보자.

결국 필요한 data에 접근하기 위해선 Memory 접근 단위인 Byte 단위로 접근해야 한다.
그래서 32 Byte 중에서 몇번째 Byte에 접근하는 지 알아야 한다.
32 = 2^5 이니 5bit로 표현가능하다.
이것을 block offset 이라고 한다.

block offset은 Memory address의 0~4번째 bit를 사용한다.
Tag
Indexing 에는 문제점이 있다.
Memory address가 이렇게 되어 있는데,
그런데 0~14번 bit가 같고 15~31번 bit가 다르다면?
Cache에선 같은 공간의 같은 data에 접근하는 것인데, 실제 접근하고자 하는 Memory data와는 다르게 되는 것이다. 이것을 충돌 났다고 말한다.
ex) 0x12345678 과 0x52345678 는 다른 Memory address 공간인데, 0~14 bit를 보면 같은 Cache 공간을 가리키게 됨.
이것을 해결하는 방법이 있다.
내가 지금 접근하려는 Memory address가 있는데, 이 address로 접근할 수 있는 Cache 공간이 굉장히 많이 있다. (충돌이 많이 날 수 있다.) 그래서 만약 충돌이 난다면, Cache 공간에 있던 data를 Memory에 저장하고 지금 접근하는 data를 Cache 공간에 넣는 방법을 사용한다.
이 과정을 위해서 Tag 가 필요하다.
Tag Matching을 하기 위해 Cache 안에 있는 data마다 tag를 달아놓는다. 32 Byte의 block이 1024개 있는데, 각각의 block 마다 tag를 달아주는 것이다.

index 와 offset 으로 사용하고 남은 나머지 bit를 tag로 사용한다. 여기선 15~31번 bit가 사용되는 것이다.
17 bit의 Tag bit를 Cache에 저장할 때, 이 tag가 유효한지 검사하는 valid bit를 1bit 추가해서 넣어서, Cache에는 18bit의 Tag bit가 들어간다.
만약 index가 같다면 tag bit로 Tag matching이란 것을 진행한다.
Tag matching
내가 접근하고 하는 Memory address에서 index 충돌이 났다고 해보자.
현재 내 Memory address의 tag bit와 Cache에 있는 tag bit를 비교하는 것을 Tag matching이라고 하는데, 이 매칭작업을 시도하게 된다.
Tag matching 과정을 살펴보자.
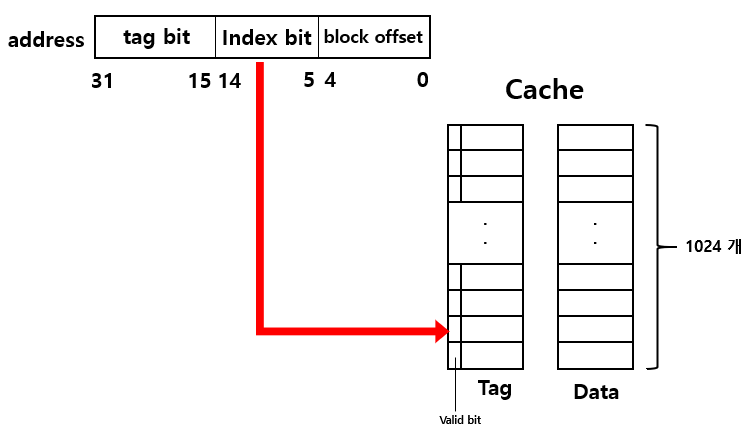
Memory address 의 index bit를 보고 Cache의 어떤 block인지 찾아간다.

Cache의 Tag를 가져와서 Valid bit가 1인지 확인한다.
Valid bit 가 0이면, Tag matching을 하지 않고, Memory에서 data를 가져온다.
Valid bit 가 1이면, Tag matching을 진행한다.
address의 tag bit 와 Cache에 있는 tag bit가 같은지 검사한다.
같으면 Hit 이고, 다르면 Miss이다.
Hit 됐다면, 내가 접근하려는 data가 맞구나 하고 data를 가져가 사용한다.
Miss 됐다면, 다른 data가 Cache에 올라와있음을 뜻한다. 이 때 원래 있던 data를 쫓아내고, 최신의 data를 cache 안에 채우게 된다.
여기서, 원래 있던 data를 쫓아내고, data를 low level에 쓰는데(Write), 쓰는 방식에 차이가 있다.
1. Write-back : data를 일단 Cache에만 쓰고 data가 쫓겨날 때 Memory 에 쓰는 방식
이 방식은 Cache에 data를 쓰는데 쫓겨나기 전까지는 Memory에 쓰지 않는다. 쫓겨날 때 data를 low level cache 또는 Memory에 쓰게 된다.
Write-back 방식은 현대에서 많이 쓰이는 방식이다.
2. Write-through : data가 update되면 Cache에도 쓰고 Memory에도 쓰는 방식
Write-through 방식은 data가 업데이트 될 때마다 Memory에 기록한다. 그래서 쫓겨날 때 따로 처리를 해주지 않아도 된다. 그러나 이 방식은 Cache에 쓸 때마다 Memory에 접근해야 돼서 비용이 많이 든다. 최근엔 많이 쓰지 않는다.
[참고]
Computer Organization and Design 5th Edition. The Hardware/Software Interface / 저자 : David A. Patterson, John L. Hennessy / 출판 : ELSEVIER
'IT > 컴퓨터구조' 카테고리의 다른 글
| [ 컴퓨터구조 ] MIPS Design Principles (0) | 2020.10.22 |
|---|---|
| [ 컴퓨터구조 ] MIPS Instructions (+Instruction to binary) (3) | 2020.10.22 |
| [ 컴퓨터구조 ] ISA (Instruction Set Architecture) (0) | 2020.09.01 |
| [ 컴퓨터구조 ] 피연산자 (Operands of Computer Hardware) (1) | 2020.05.01 |
| [ 컴퓨터 구조 ] 하드웨어 연산 (Operation of Computer Hardware) (0) | 2020.05.01 |




댓글