MIPS Instructions (+Instruction to binary)
MIPS instruction의 종류와 instruction이 어떻게 binary code로 바뀌는지 살펴보자.
사람과 컴퓨터는 소통해야 한다.
소통하는 과정은 크게 3가지로 볼 수 있다.

High-Level Language ( C언어 ) 가 compiler를 통해 MIPS Assembly Language로 변환되고, Assembler를 통해 기계가 이해할 수 있는 Binary machine Language로 변환된다.
여기서 MIPS Assembly Language 단계에서 예를 하나 들어보자.
add $t0, $s1, $s2
$s1 과 $s2 를 더해 $t0 에 저장하라는 뜻이다.
이것은 하나의 명령어, 즉 하나의 instruction이 될 수 있다.
이러한 MIPS instruction의 종류는 총 3가지가 있다.
1. R format
2. I format
3. J format
1. R format

MIPS 명령어의 R format은 위와 같이 이루어져 있다.
opcode : instruction이 수행할 연산의 종류. 연산자.
rs : first oprand register (source)
rt : second oprand register
rd : destination register
shamt : shift amount
funct : function. opcode가 연산의 종류를 표현했다면, funct 필드는 그 중의 한 연산을 구체적으로 지정한다.
R format은 레지스터 number를 이용하여 add, addu, and, sll, srl 등의 연산을 수행할 수 있다.
R format의 instruction 예시와 함께 이것이 어떻게 binary로 바뀌는지 살펴보자.
MIPS instruction -> Binary machine code
add instruction 으로 예를 들어보자.
add $t0, $s1, $s2
먼저, MIPS Green Sheet에서 add instruction이 어떻게 구성되어 있는지 봐야한다.
instruction은 MIPS Green Sheet에 모두 나와있다.
MIPS Green Sheet PDF <- 이 PDF 파일에서 add를 찾아보자.

1. add의 format은 R이고
2. rd rs rt 순서대로 읽고,
3. opcode는 0이고,
4. funct는 20(hex)인 것을 확인할 수 있다.
그렇다면
1. op rs rt rd shamt funct 순서로 binary code가 만들어짐을 알 수 있고
2. add $t0, $s1, $s2 여기에서 rd=$t0, rs=$s1, rt = $s2 라는 것을 알 수 있고
3. opcode는 0이고
4. funct는 16진수로 20인 것을 알 수 있다.
이제 알 걸 알았으니 바꿔보도록 하자.
이 R format에 add $t0, $s1, $s2 를 넣어보면 아래와 같다.

이것을 10진수로 표현하면 아래와 같다.
(참고) register는 각자 번호가 매겨져있다. ($s1=17, $s2=18, $t0=8)

이것을 그대로 binary code로 표현해보면 아래와 같다.

add $t0, $s1, $s2 에서 00000010001100100100000000100000 으로 바뀌는 과정을 살펴보았다.
그런데 문제점이 하나 있다. 5bits 필드로는 2^5 = 32 보다 큰 수를 표현할 수 없다.
32보다 큰 상수나, 주소값이 오게 된다면 표현할 수 없다는 것이다.
따라서 5bits 필드보다 큰 필드가 필요하게 되었다.
결국 16bits를 표현할 수 있는 I format을 만들게 되었다.
엇, 그런데 설계원칙에서는 형태를 통일하라는 원칙이 있었는데? 왜 3개로 나뉘게 만들었지?
여기서 설계 원칙이 또 등장한다.
Design Principle 4: Good design demands good compromises
좋은 설계에는 적당한 절충이 필요하다.
모든 명령어의 길이를 같게 하고 싶은 생각과 명령어 형식을 한가지로 통일하고 싶은 생각 사이에서 충돌이 생기게 된 것이다. 여기서 설계자들이 택한 절충안은 모든 명령어의 길이(32bits)를 같게 하되, 명령어 종류에 따라 형식(R,I,J format)은 다르게 하는 것이었다.
2. I format

op : 연산자
rs : base register
rt : destination register
constant : 표현범위는 -2^15 ~ 2^15 -1 이다.
address : offset. rs의 주소값으로부터 얼마나 떨어져 있나를 표시한다.
I format은 R format과 달리 16bits를 이용해 상수와 주소표현이 가능하다. 그래서 주소값을 가져오는 bne, beq, lw, sw 등의 분기문과 상수연산을 하는 addi, addiu, andi 등이 가능하다.
그런데 과연 16bits로 상수값과 메모리 주소값을 전부 표현할 수 있을까?
1) 상수값
우선, 프로그램에서 사용하는 대부분의 상수값은 작아서 16bits로 표현이 가능하다.
그렇다는건 16bits보다 큰 상수가 나올 때도 있다는 말이다. 그 때는 어떻게 해야하나?
바로 상위 16bits와 하위 16bits를 lui, ori 를 사용하여 32bit 상수를 표현하면 된다.
예시를 들어보자. $s0에 아래 32bits 상수를 채워보자.
0000 0000 0011 1101 0000 1001 0000 0000
1. lui를 통해 상위 16bits를 채운다.
상위 16bits = 0000 0000 0011 1101(two) = 61(ten)
lui $s0, 61
=> 현재 $s0 = 0000 0000 0011 1101 0000 0000 0000 0000
2. ori를 통해 하위 16bits를 더한다.
하위 16bits = 0000 1001 0000 0000(two) = 2304(ten)
ori $s0, $s0, 2304
=> 최종 $s0 = 0000 0000 0011 1101 0000 1001 0000 0000
32bits 상수값을 표현할 때, 이렇게 I format instruction인 lui와 ori를 통해 32bits 상수값을 표현하면 된다.
2) 주소값
I format에서 주소값을 표현할 때는 조건부 분기의 경우이다. (bne, beq) 조건부 분기는 주로 반복문이나 조건문에서 사용되므로, 대부분 가까이 있는 범위로 분기한다고 볼 수 있다. 이는 대부분 2^16 word 이내로 분기한다고 말할 수 있다.
현재 위치로부터 얼만큼 떨어져 있나를 표시해주면 된다. 이것을 PC-relative addressing (PC 상대 주소지정)라고 한다.
분기문을 생각해보자.
조건이 맞으면 목표 위치까지 이동해야한다. 이 목표 위치. 즉, 목표 위치의 주소값을 어떻게 구할까?
현재 메모리에서 내가 있는 주소값인 PC(Program Counter)를 어떤 레지스터 주소값에 분기 주소를 더해주면 된다.
PC = 레지스터 + 분기주소 라고 말할 수 있다.
무슨말이지..?
내가 이동하고 싶은 메모리 주소는 내가 현재있는 주소값에서 얼마나 떨어져 있는지를 더해줌으로써 구하면 된다.
즉, 타겟 주소 = 현재 주소 + 떨어진 거리 이다.
그리고 이 타겟 주소를 현재 가리키고 있는 주소(PC)라고 지정해주면 된다.
그러면 현재 가리키고 있는 주소(PC)가 이동하고 싶은 메모리 주소를 가리키게 된다.
그래서 16bits 필드엔 뭐가 들어가는 거야?
타겟 주소 = 현재 주소 + 떨어진 거리
이것은 이렇게 표현할 수 있다.
타겟 주소 = 현재 주소 + offset*4
여기서 offset이 16bits 필드에 들어가게 된다.
(주의)
나중에 배우지만, 하드웨어 입장에서는 PC를 미리 4 만큼 증가시켜 놓는다.
즉, 실제 MIPS 주소는 PC를 기준으로 하는 것이 아니라, (PC+4) 를 기준으로 하게 된다.
그래서 실제론 이동하고 싶은 메모리 주소를 (현재주소+4 + 떨어진 거리)로 구해주어야 한다.
MIPS instruction -> Binary machine code
lw $t0, 1200($t1)
lw로 예시를 들어보자.
(참고) 이것을 말로 해석해보면, $t1(주소값)에서 1200만큼 더한 곳의 주소값을 $t0에 저장하는 것이다.
즉, 배열로 따지면 300크기만큼 공간이 생겼다고 말할 수 있다. (배열의 한칸의 크기는 4byte이기 때문에 300*4 = 1200)
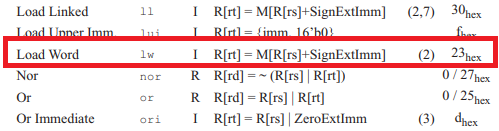
MIPS Green Sheet를 보니
1. format은 I 이고
2. rt constant(or address) rs 순서대로 읽으면 되고
-> 사람이 instruction 읽을 때의 기준의 순서대로. $t0 > 1200 > $t1 순서.
3. opcode는 23(hex) 라는 것을 볼 수 있다.
그러므로
1. op rs rt constant(or address) 순으로 binary code가 만들어짐을 알 수 있고
2. lw $t0, 1200($t1) 에서 rt=$t0, rs=$t1, constant=1200 인 것을 알 수 있고
3. opcode는 16진수로 23이라는 것을 알 수 있다.
이제 I format instruction에서 binary 로 바꿔보자.
lw $t0, 1200($t1) 를 바로 10진수로 표현하면 아래와 같다.

이것을 binary code로 표현하면 아래와 같다.

lw $t0, 1200($t1) 를 10001101001010000000010010110000 으로 바꾸었다.
3. J format

op : 연산자
address : 주소
I format에서 16bits로 주소를 표현하지만, J format은 26bits로 주소값을 표현한다.
가장 심플한 형태이다. J 와 Jal 이 J format에 속한다.
그런데 이 26 bits로도 모든 주소값을 표현하기 힘들다.
어떻게 32bits로 표현할 수 있을까?
1. byte 주소가 아닌 워드 주소를 사용해서, 26bits의 4배만큼의 28 bits로 표현가능하다.
byte 주소로 80000 인 곳으로 Jump 한다고 하면, address에는 word 단위로 표현해 80000/4 = 20000이 저장되어 있다.
그래서 address * 4 로 28bits만큼의 주소를 표현할 수 있다.
4를 곱해주는 것은 left shift 2번 해준것과 똑같다.
2. 나머지 4bits는 PC의 상위 4bits를 가져와서 표현한다.
즉, PC가 0010 0000 0000 0000 0000 0000 0000 0000 이라면
상위 4bits인 0010 을 가져오는 것이다.
PC 상위 4bits는 바뀌지 않은 채로 표현된다. 이는 MIPS의 단점이라고 말할 수 있다.
MIPS instruction -> Binary machine code
Loop: ....
....
J Loop
Exit :
(Loop의 주소값 : 80000)
J의 op는 2(hex)이다.
J Loop 에서 Loop의 주소값/4 를 address에 넣어준다. (word 단위로 넣은 것임)

이를 binary로 표현하면 아래와 같다.

이렇게 binary로 표현하였다.
현재 표현된 address는 00 0000 0000 0100 1110 0010 0000 은 26bits이다. 이것으로 타겟 주소를 찾는 것도 살펴봐보자. 즉, 26bits의 address를 32bits로 확장하는 과정을 살펴보자.
1. left shift 두번
address = 0000 0000 0001 0011 1000 1000 0000
2. PC bits에서 상위 4개의 bits를 가져와서 address의 상위 4bits로 사용한다.
(PC = 80024 이라고 가정. 32bits로 표현하면 PC = 0000 0000 0000 0001 0011 1000 1001 1000)
address = 0000 0000 0000 0001 0011 1000 1000 0000
26bits인 address 00 0000 0000 0100 1110 0010 0000 를
32bits인 address 0000 0000 0000 0001 0011 1000 1000 0000 로 표현하였고, 이 주소는 타겟 주소가 된다.
[참고]
Computer Organization and Design 5th Edition. The Hardware/Software Interface / 저자 : David A. Patterson, John L. Hennessy / 출판 : ELSEVIER
The Jump Instruction - chortle.ccsu.edu/AssemblyTutorial/Chapter-17/ass17_5.html
'IT > 컴퓨터구조' 카테고리의 다른 글
| [ 컴퓨터구조 ] Cache (5) | 2020.12.09 |
|---|---|
| [ 컴퓨터구조 ] MIPS Design Principles (0) | 2020.10.22 |
| [ 컴퓨터구조 ] ISA (Instruction Set Architecture) (0) | 2020.09.01 |
| [ 컴퓨터구조 ] 피연산자 (Operands of Computer Hardware) (1) | 2020.05.01 |
| [ 컴퓨터 구조 ] 하드웨어 연산 (Operation of Computer Hardware) (0) | 2020.05.01 |




댓글